Learning Invisible Markers for Hidden Codes in Offline |
您所在的位置:网站首页 › connect online to meet offline翻译 › Learning Invisible Markers for Hidden Codes in Offline |
Learning Invisible Markers for Hidden Codes in Offline
|
摘要
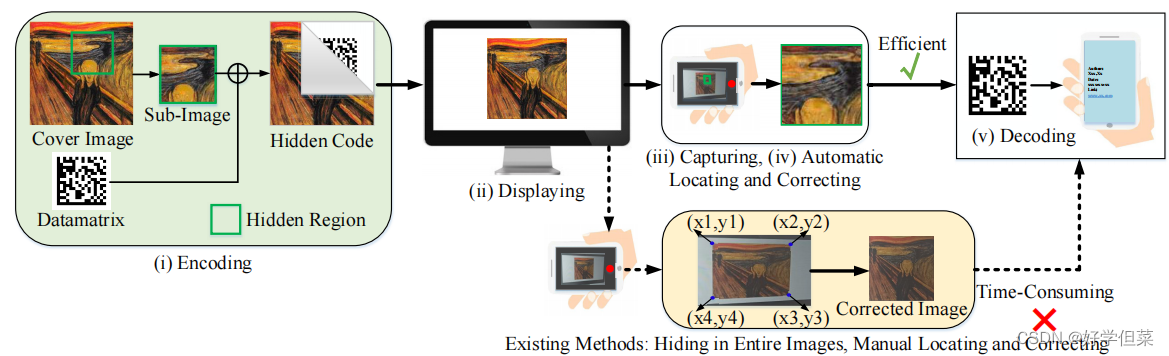
QR(快速响应)代码被广泛用作离线在线渠道,将宣传材料(如链接)(如显示和打印)传递到移动设备。然而,二维码并不利于占用宝贵的宣传材料空间。最近的研究提出了不可见的代码/超链接,可以将隐藏的信息从离线传递到在线。然而,它们需要标记来定位不可见代码,但由于标记,无法达到不可见代码的目的。本文提出了一种新的显示/打印相机场景的不可见信息隐藏架构,包括隐藏、定位、纠正和恢复,其中不可见的标记被学习,使隐藏的代码真正不可见。我们将信息隐藏在一个子图像中,而不是隐藏在整个图像中,并在端到端框架中包含一个本地化模块。为了实现高视觉质量和高恢复鲁棒性,提出了一种有效的多阶段训练策略。实验结果表明,该方法在视觉质量和鲁棒性方面都优于目前最先进的信息隐藏方法。此外,隐藏码的自动定位显著减少了人工校正照片的几何失真的时间,这是移动应用中信息隐藏的革命性创新。 1、介绍用智能手机扫描二维码,方便人们随时随地获取从离线到在线的信息。然而,随着对体验质量(QoE)需求的不断增加,不美观的外观限制了QR码在许多场景中的应用,如交互式视觉媒体和用户生成的IP保护(UGG)。为了在保持良好的QoE的同时实现离线到在线的体验,隐形信息隐藏成为一种新的替代[11,20]。在显示/打印相机场景中隐藏信息的核心要求是使信息对人眼看不见,但可被移动设备检测到。 在显示/打印摄像机场景中,隐藏不可见信息的一般过程包括五个步骤:(i)对图像中的信息进行编码,(ii)显示/打印,(iii)捕获,(iv)定位编码信息并纠正几何失真,(v)解码。上述过程的主要挑战是,解码过程需要从包含由相机成像过程造成的失真的照片中恢复隐藏的信息。这些失真根据其来源可分为三类:(i)来自环境,例如亮度、对比度和颜色失真,(ii)来自相机侧面,例如离焦模糊、噪声和压缩,(iii)来自摄影师侧面,例如运动模糊和几何失真。我们将包含隐藏信息的图像定义为被编码的图像。现有的方法[7,8,11,20,25]可以恢复上述扭曲条件下的隐藏信息。然而,这些方法假设提供了编码图像在照片中的四个顶点的坐标,从而可以通过进行透视变换来纠正几何失真。因此,这些方法需要进行预处理来定位编码图像的四个顶点,并从不同角度拍摄的照片对编码图像进行校正,这是解码成功的关键。 现有的常用于消除几何变形的预处理方法包括两类:手动定位[8,25]和自动定位[7,11,20]。手动定位是为了手动查找已编码图像的四个顶点,如图1所示。然而,手动定位顶点坐标非常耗时,而且当隐藏代码不可见时有时会很困难。传统的自动定位需要额外的标记,以便将带有失真的编码图像与背景区分开来。这些方法在编码图像周围添加可见标记,例如边界框 [11] 和条形码 [7]。然而,这些标记打破了隐形代码的不可见性。除了传统的自动方法外,Tancik等人提出了StegaStamp,这是一个端到端可训练的框架。[20]它的编码器和解码器由卷积神经网络(CNN)组成。在训练过程中,StegaStamp使用一系列可微失真操作对编码的图像进行处理,并将失真图像输入其解码器。因此,解码器可以学习在不同的失真情况下定位和恢复信息。然而,实验结果表明,基于CNN的解码器容易受到几何失真的影响,因此仍然需要额外的标记(白色边界)来定位[20]中编码的图像。
图1。并将所提方法与以往的方法[7,8,11,20,25]进行了比较。与以往的方法相比,该方法能够自动定位包含隐藏信息的准确位置,在移动应用中是有效的。 本文提出了一种新的显示/打印摄像机场景中的隐形信息隐藏模型,该模型通过学习隐形标记来自动定位隐藏信息(数据矩阵)。受[11,20]的启发,提出的模型是一个基于CNN的端到端框架,由编码器、失真网络、定位网络和解码器组成。 与[7,8,11,20,25]不同的是,编码器将信息(数据矩阵)隐藏在一个子图像中,而不是隐藏在整个覆盖图像中,这样,子图像之外的图像区域就被认为是照片中的背景。失真网络的作用类似于[20],解码器从失真的子图像中恢复信息。我们首次在失真网络和解码器之间添加了一个定位网络。与人工定位或添加人工标记不同,编码器和定位网络的联合训练使编码器学习在子图像周围生成不可见标记,而定位网络学习在各种失真,特别是几何失真下检测这些不可见标记。换句话说,优化的目标是使隐藏码的标记对人眼看不见,但可以被定位网络检测到。给定检测到的子图像的坐标,我们可以消除几何失真,使解码器只需要从校正后的子图像中恢复信息。本文的主要贡献总结如下: • 我们在显示/打印摄像机场景中提出了一种新的不可见信息隐藏架构,包括信息隐藏、定位、校正和信息恢复。 • 我们首次学习了不可见标记,并在端到端框架中为隐藏代码开发了一个本地化模块。编码器和定位网络的联合训练产生人眼不可见但定位网络可检测的标记,这在不破坏视觉不可见性的情况下显著减少了纠正几何失真的时间。 • 为了在不可见标记的可检测性、隐藏码的恢复精度和视觉不可见性之间实现良好的权衡,我们提出了一种有效的多阶段训练策略。设计了一系列的损失函数,使包含隐藏信息的子图像对人眼感到舒适。 2、相关工作随着物联网的发展,条形码已经成为连接物理世界和虚拟世界的最重要的媒介。然而,条形码的外观不美观,占用了宝贵的宣传材料空间。为了解决这些局限性,人们提出了许多美学条形码[1-4,9,10],它们将条形码隐藏在自然图像中,并保留可见的标记用于定位。 不可见的信息隐藏:隐藏信息包括两个主要分支:隐写术和数字水印。隐写术被广泛地应用于信息安全领域。根据信息安全的要求,隐写算法需要较高的信息能力和抗隐分析[14]的安全性。根据信息隐藏的领域,隐写术可分为空间隐写术,如最低有效位(Least Significant Bit, LSB)和变换域隐写术。(隐写术(二)--传统数字图像隐写算法 - 简书 (jianshu.com))最近,提出了多种基于深度神经网络的方法。 与隐写术不同,数字水印的主要应用是产权保护,这要求水印恢复的准确性较高,而不是较高的安全性和信息能力。数字水印还包括空间水印[13,17]、变换域水印[5,7,8,21]和基于DNN的水印[11,15,20,27,29]。最近,提出了一些方法来取代离线到在线消息[7,8,11,20]中的作用。由于这些方法不考虑在体系结构中定位隐藏的代码,因此在实际应用中,手动定位隐藏的代码或添加可见的标记对它们检测所编码的图像是必要的。 3、方法学如图2所示,所提出的模型是一个端到端框架,包括编码器、失真网络、定位网络和解码器。下面的小节将详细描述这些模块。
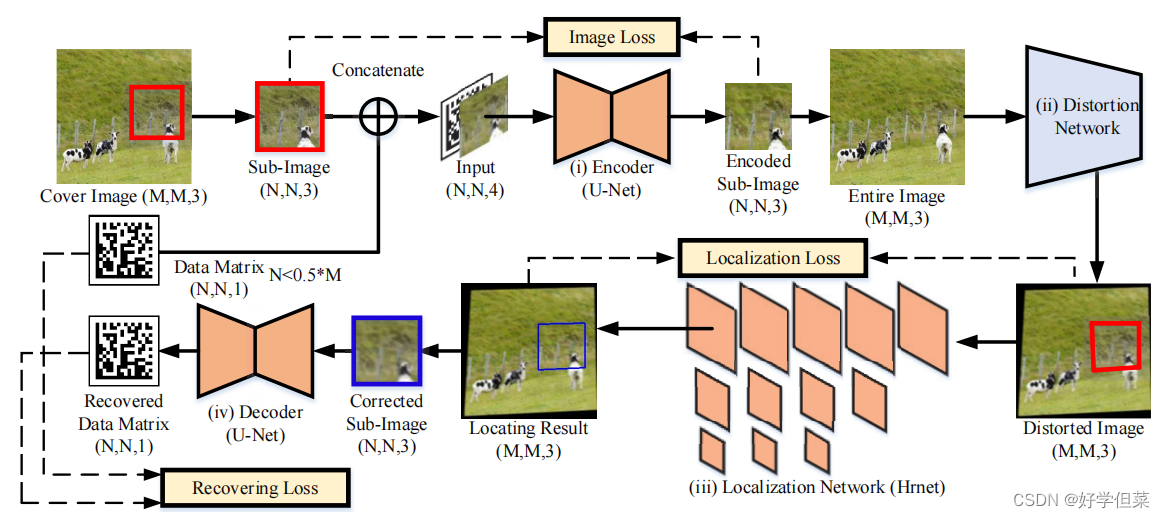
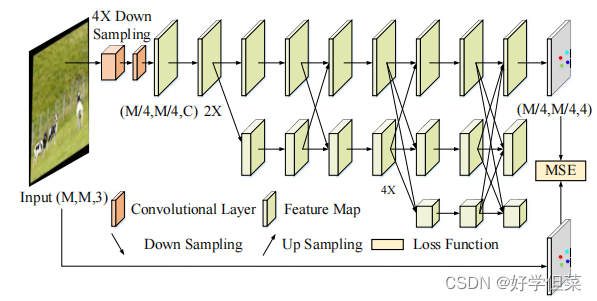
图2: 所提出的模型的管道。该编码器在整个覆盖图像的子图像中隐藏了一个数据矩阵。失真网络应用可微操作对包含已编码子图像的整个图像进行处理。定位网络定位了失真子图像的准确位置。根据定位结果,对子图像的几何失真进行校正,解码器从校正后的子图像中恢复隐藏的数据矩阵。 3.1编码器编码器将信息隐藏在覆盖图像的选定子图像中的信息,使隐藏的数据矩阵对人眼不可见。封面图像为256×256RGB图像,子图像为封面图像的96×96子区域,隐藏信息为96×96数据矩阵。我们将数据矩阵连接到子图像的最后一个通道,生成一个96×96×4张量,并将该张量作为输入发送到编码器。我们使用U-Net [18]作为编码器,它接收96×96×4张量,并输出一个96×96RGB图像。编码后,我们将原始的子图像替换为编码的子图像。 3.2失真网络从数字图像到照片的成像过程可能会导致显示/打印图像的质量下降。受[11,20,29]的启发,我们在编码器和定位网络之间插入一个失真网络,来模拟相机成像过程造成的质量下降。在训练过程中,失真网络使用可微图像处理操作对编码后的整个图像进行处理,但不包含任何推理参数。在失真网络的帮助下,定位网络和解码器可以学习抵抗这些失真。 根据这些失真的来源,我们将失真分为三类: (i)环境因素(亮度、对比度和颜色失真)造成的失真,(ii)相机侧面造成的失真(高斯模糊、随机噪声和JPEG压缩),(iii)摄影师侧面造成的失真(运动模糊和几何失真)。这些失真的实施细节和设置在补充材料中提出。 3.3定位网络为了从整个失真图像中定位所编码的子图像,所提出的架构在失真网络和解码器之间插入了一个定位网络。定位网络接收整个失真图像(256×256×3),预测每个顶点的热图(64×64×4),并根据预测的热图Hpre计算每个顶点的坐标。定位网络是HRNet [23]的一个变体版本,它是一个具有并行的多分辨率子网络和重复的多尺度融合的架构。图3展示了HRNet的简化体系结构。定位网络接收到失真图像后,使用3×3核和步幅为2的两个卷积层来处理输入图像,然后将下采样的特征映射发送到HRNet的第一个高分辨率模块。 本文使用的HRNet包括四个不同规模的并行子网络(由于篇幅有限,图3给出了三个并行子网络)。通过多尺度特征提取和多尺度特征融合,第一尺度的最终特征图(图3的第一行)具有足够的信息,可以预测每个顶点的热图。为了监督四个顶点的坐标的回归,我们将坐标值转换为热图Hgt(64×64×4)作为基本真相。采用二维高斯分布,以每个顶点的坐标值为中心,标准差为1像素,生成真实热图Hgt。经过预测后,我们将热图转换为坐标值,根据坐标计算一个透视矩阵,并使用透视变换来校正所编码的子图像的几何失真。校正后的子图像的大小为96×96×3。
图3.定位网络的架构(HRNet) 3.4解码器解码器接收校正后的编码子图像(96×96×3)并恢复隐藏数据矩阵(96×96×3)。解码器的结构与编码器[18]相同。尽管在定位网络的帮助下已经消除了几何失真,但解码器输入与原始图像相比仍然存在其他失真,例如噪声、模糊以及亮度和对比度的变化。这些失真来自对失真网络的处理,帮助解码器学会在这些失真下恢复隐藏的数据矩阵。 在[20]中,Tancik等人发现,通过将几何扭曲的图像输入解码器,很难使解码器学会抵抗几何失真。此外,为了使隐藏信息在几何失真条件下可解码,[20]的编码器将牺牲所生成图像的视觉质量。因此,在定位网络的帮助下,我们的解码器可以专注于恢复除几何失真外的其他失真下的信息。 3.5训练策略在描述训练策略之前,我们分析了每个模块的优化目标。编码器旨在实现编码图像良好的视觉质量,定位目的是找到失真下的目标子图像,解码器是恢复除几何失真外的失真下的隐藏信息。然而,如果我们在一开始就共同训练这三个模块,很难在这些竞争目标之间实现良好的权衡。因此,我们提出了一种有效的多阶段训练策略,以实现视觉质量和鲁棒性之间的良好权衡。 3.5.1第一阶段在这一阶段,我们只优化了定位网络和解码器。优化定位网络的损失函数定义为Lloc:
式中,w为地图宽度,Hgt为ground-truth热图,Hpre为HRNet预测的热图。优化解码器的损耗函数定义为Ldec:
式中,dm为ground-truth数据矩阵,dm为U-Net恢复的数据矩阵。本阶段的总损失函数公式如下:
其中,λ1和λ2分别设置为30和1 3.5.2第二阶段在第一阶段之后,我们的模型可以准确地定位编码子图像,并从编码子图像中恢复数据矩阵,而不会出现几何失真。然而,由于我们没有对编码器进行优化,而端到端的训练也在Lloc和Ldec的监督下更新了编码器的参数,所以编码器编码后的子图像的视觉质量较差。因此,我们将Lpix和Lperp用于第二阶段,如下所示:
其中 Lpix 是 L2 范数,Lperp 是 LPIPS [28]。 λ1 和 λ2 设置为与第一阶段相同的值,λ3 和 λ4 设置为 1。 3.5.3第三阶段通过对上述阶段的优化,生成的子图像可以获得良好的视觉质量,而定位网络和解码器可以保持良好的性能。但是,与原始的子图像相比,生成的子图像在其边缘有明显的标记和四个顶点,如图9所示。从可解释性的角度来看,这些标记是通过对编码器的端到端训练和定位来学习的。编码器生成这些标记,以帮助定位网络找到在失真情况下的编码子图像。因此,这一阶段的优化目标是降低这些标记的可见性,同时保持定位网络对这些标记的敏感性。受[20]的启发,我们提出了一个余弦增益方案来实现上述目标。 在形式上,我们将一个权重矩阵定义为:
式中,N为子图像的宽度,s为4,(i,j)表示像素坐标,dx/y为沿x轴或y轴到边的距离。当dx/y
在本文中,fcos是10。第三阶段的总体优化目标表述为:
其中Lgain为Lcos或Lgau时,λ5设置为1,λ1、2、3、4设置为与上述阶段相同的值。 4.实验结果 4.1数据集训练集由PASCAL VOC 2012[6]的1200张图像组成。测试集由PASCAL VOC 2012[6]的300张图片和RIHOOP[11]使用的100张图片组成。封面图片大小为256×256×3,子图片大小为96×96×3。隐藏数据矩阵由pylibdmtx1生成,它是一个16×16矩阵。为了与子图像对齐,我们将数据矩阵的大小调整为96×96像素。数据区域的总位数为196,其中编码数据的长度为96位,其他位表示纠错码和填充码。 4.2超参数设置如3.5节所述,培训过程分为三个阶段。在训练中,我们分别对第一阶段、第二阶段和第三阶段的训练使用800个epoch、1000个epoch和300个epoch。如果一次训练所有的损耗,解码和定位损耗很难收敛。Eq. 7的权重参数设置为:λ1=30, λ2=1, λ3=1, λ4=1, λ5=1。训练策略的参数设置在3.5节中介绍,失真层的设置在3.2节中介绍。我们选择Adam作为优化器,并设置初始学习率为10−4。在每个训练阶段,学习率随余弦退火计划衰减,直到衰减到4×10−5。批大小为32。 4.3.评价指标我们使用联合网络上的交集(IoU)作为度量来评估本地化网络的性能:
其中Areapre是局部子图像的区域,Aeragt为地面真实区域。为了评估解码器的性能,我们使用比特误码率(BER)和像素误码率(PER)作为评价指标::
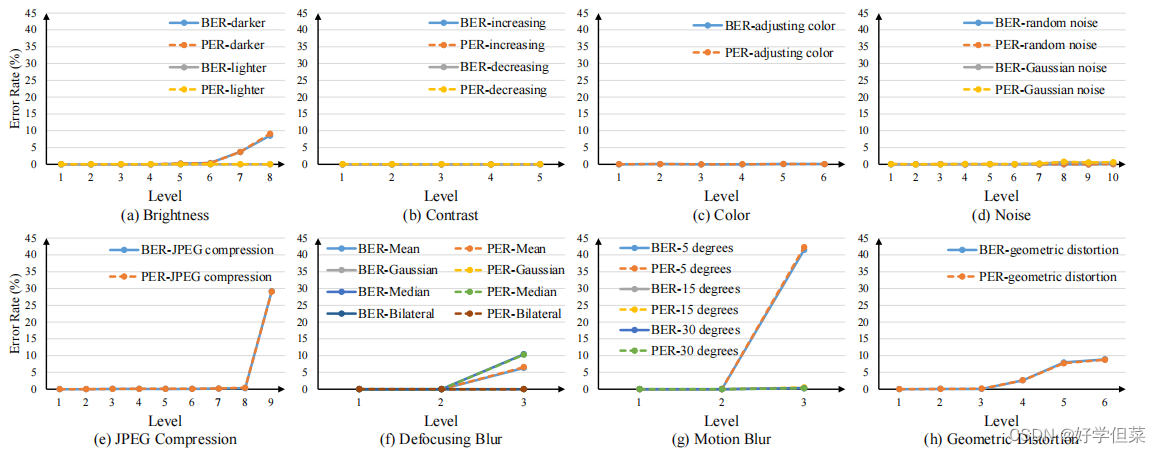
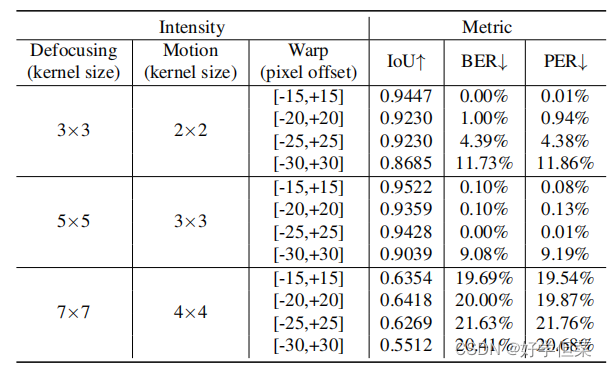
其中nerr为错误比特数,len(str)表示隐藏消息的长度,perr为错误像素数,size(数据矩阵)表示数据矩阵的分辨率。此外,我们用PSNR和SSIM[24]来评价视觉质量。 4.4基于仿真的鲁棒性测试在本节中,我们将测试我们的模型对合成失真的鲁棒性。除了在训练中使用的失真外,我们还通过添加在训练中未知的失真类别来测试模型对未知失真的泛化能力。对于每个失真类别,我们设置了不同的失真级别。关于这些设置的更多细节将在补充材料中介绍。我们在图4中展示了不同失真类别下的解码结果。从图4中,我们可以发现我们的模型很容易受到JPEG压缩和运动模糊的影响。此外,从图4可以看出,我们的模型对训练中的未知失真(如高斯噪声、中值模糊和双边滤波)具有鲁棒性。在这个实验中,我们发现定位结果的错误会导致解码失败。例如,当JEPG的质量因子为10时,平均IoU仅为0.25,因此发送到解码器的子图像不包含全部信息。我们在表1中展示了欠条和错误率之间的相关性。
图4。不同失真情况下解码结果的误码率(BER)和像素误码率(PER)。
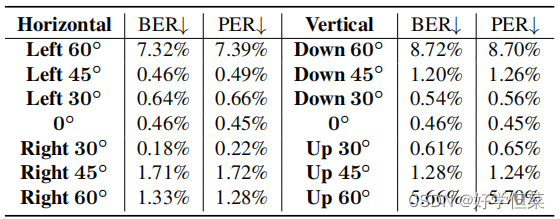
表1.散焦模糊、运动模糊(度=15◦)和几何失真组合下的IoU、BER和PER 4.5.野性健壮性为了进一步验证所提出的信息隐藏模型在真实场景中的实用性,我们在不同的拍摄条件下捕获了大量的照片,以测试我们模型的鲁棒性。在这些实验中,我们使用两款智能手机(红米Note 9和iPhone 10)来验证对不同相机的泛化能力。显示器为戴尔S2421HSX,本实验中的打印机为彩色消费型打印机。我们从不同的拍摄角度和不同的拍摄距离拍摄这些照片。 4.5.1对不同拍摄角度的鲁棒性在本次实验中,我们固定摄像机的位置,调整显示器的朝向,模拟不同的拍摄角度,如图5所示。我们将显示器和智能手机之间的距离设置为40厘米。因为生成的图像以原始分辨率显示,没有任何缩放,所以我们大致裁剪出编码图像的区域,并调整裁剪区域的大小为256×256,如图5所示。图5的第一行显示原始照片,第二行显示调整后图像的定位结果。与[11]和[20]不同的是,这个过程不需要手动查找编码图像的精确顶点,也不需要在编码图像周围添加白色边框。不同拍摄角度下的解码结果如表2所示。当拍摄角度是60◦向下,错误率是最高的,但仍然低于10%。结果表明,我们的模型对于不同角度的拍摄具有足够的鲁棒性。
图5.在不同垂直拍摄角度下拍摄的照片及相应的定位和解码结果。
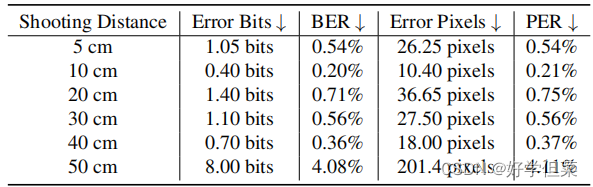
表2。不同拍摄角度下的解码结果 4.5.2对不同射击距离的鲁棒性在本实验中,我们固定显示器的方向,调整拍摄距离(5 cm、10 cm、20 cm、30 cm、40 cm和50 cm)。我们在表3中显示了解码结果,在图6中显示了一些可视化结果。图6中的目标子图像由于不同的拍摄距离造成的比例而具有不同的分辨率。在将这些子图像输入到定位网络之前,我们将这些子图像调整为256×256。定量结果表明,该模型对不同的射击距离具有足够的鲁棒性。
图6.在不同拍摄距离下拍摄的照片及相应的定位和解码结果
表3。不同射击距离下的解码结果 4.5.3对打印图像的鲁棒性在本实验中,我们测试了模型在打印相机场景下的鲁棒性。我们在图7中展示了一些例子,其中的照片包括不同的照明条件和不同的背景。红米Note 9的平均BER和PER分别为1.37%和1.38%。iPhone 10的平均BER和PER分别为0.27%和0.28%。这些结果表明,我们的模型对打印图像具有足够的鲁棒性,并能很好地推广到不同的相机模型。
图7.打印后拍摄的照片。这些例子包括不同的照明条件和不同的背景 4.6与最先进的方法进行比较在本节中,我们将我们的模型与最先进的方法:StegaStamp[20]和RIHOOP[11]进行比较。StegaStamp和RIHOOP都是基于深度学习的信息隐藏方法,对相机成像过程具有鲁棒性。我们使用4.1节中描述的训练集对StegaStamp[20]和RIHOOP[11]进行再训练,以进行公平的比较。对比结果见表4。由于[20]和[11]的图像大小与我们的不同,我们根据不同模型的分辨率之比来调整几何失真的范围。我们在图8中展示了这三个模型的一些生成图像。从表4可以看出,我们的方法对几何畸变的鲁棒性要比[20]和[11]强得多。对于视觉质量,我们的方法达到了与[11]相当的客观评分,并显著优于[20]。即使考虑到纠错码,我们的模型也能够隐藏比[11,20]更多的比特。
图8。将原始图像与生成的图像进行比较。[20]和[11]在整个图像中隐藏信息,无法控制隐藏区域。因此,生成的[20]和[11]图像在低频区域,如墙壁和天空,有显著的质量下降
表4.与最新方法的比较结果 4.7 消融实验 4.7.1.定位网络的影响在本节中,我们比较了定位网络与手动定位的效果。在使用定位网络时,根据检测到的坐标去除几何畸变。在使用手动定位时,我们手动查找子图像的顶点并去除几何畸变。对比结果如表5所示,其中失真1表示亮度、对比度和颜色失真的组合,失真2表示随机噪声和JPEG压缩的组合。结果表明,与人工定位相比,定位网络可能会牺牲少量的解码精度,但可以显著减少预处理时间。在移动应用中,相对于运行效率的显著提高,定位结果带来的解码误差可以忽略不计。
表5 有和没有定位网络的解码结果 4.7.2对边缘增益方案的影响在本节中,我们通过训练两个模型来验证所提出的边缘增益方案的效果。第一个模型没有使用3.5.3节提出的边缘增益损失函数,第二个模型使用该损失函数。表6显示,边缘增益如预期的那样提高了生成图像的视觉质量。此外,还提高了定位网络和解码器的性能。为了避免两个训练过程的随机性,我们在第一个模型的基础上,利用边缘增益损失对参数进行优化。然后,我们使用没有边缘增益的模型来生成测试图像。之后,我们使用这两种模型对图像进行解码。结果表明,利用所提出的边缘增益对模型进行微调,可以提高定位网络的性能(IoU↑从0.8866增加到0.9403)和解码器(BER↓从11.29%下降到8.59%,PER↓从11.53%下降到8.56%)。可视化的结果如图9所示,表明边缘增益方案消除了可见边缘对HVS的影响。
表6.提出的边缘增益的消融结果
图9 比较了有余弦边缘增益损失函数和不有余弦边缘增益损失函数的编码器的性能 4.7.3子图像选择的效果在本小节中,我们分析了隐藏子图像选择的效果。对于同一幅图像,我们将相同的数据矩阵隐藏在两个不同的子图像中:(1)低频区域,如人脸和天空;(2)高频区域,如动物皮毛和草。与隐藏在低频区域相比,隐藏在高频区域显著增加了隐藏信息的视觉不可见性,但鲁棒性降低(BER增加9.35%,PER增加9.69%,IoU减少3.75%)。 4.8限制这一部分描述了我们模型的局限性。除了像第4.4节那样容易受到JPEG压缩和运动模糊的影响外,当几何失真程度超过训练中的可学习范围时,定位误差太大而无法恢复数据矩阵。这一现象表明,学习到的标记与子图像和背景之间的相对位置有关。我们在图10中提供了一些失败的例子。此外,当编码区域的大部分区域被遮挡时,我们的模型容易受到攻击。
图10 一些故障示例:(a-1)太暗、(a-2)运动模糊、(a-3)JPEG压缩、(a-4)和(a-5)几何失真、(B)遮挡 5.结论本文提出在离线到在线的摄影(即显示/打印相机场景)中,学习和检测隐藏代码的不可见标记。提出了一种有效的多阶段训练策略,以实现较高的不可见性和可检测性。实验结果表明,该方法对一般拍摄条件具有鲁棒性,而不需要进行耗时的预处理来定位和纠正相机成像过程中具有几何失真的编码图像。 |
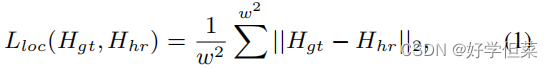
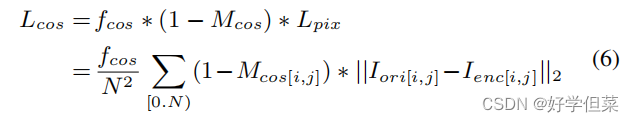
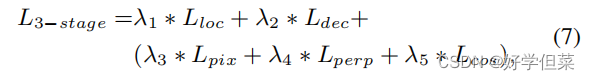
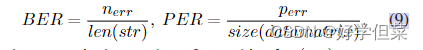









【本文地址】